Home
/ How Does Hadoop Work : See full list on readwrite.com
How Does Hadoop Work : See full list on readwrite.com
How Does Hadoop Work : See full list on readwrite.com. How do i get started with hadoop? Mapreduce, as noted, is enough of a pressure point that many hadoop users prefer to use the framework only for its capability to store lots of data fast and cheap. B) it integrates big data into a whole so large data elements can be processed as a whole on multiple computers. How to get started hadoop? That's why hadoop is likely to remain the elephant in the big data room for some time to come.
There are two daemons running for yarn. Before learning how hadoop works, let's brush the basic hadoop concept. The file gets divided into a number of blocks which spreads across the cluster of commodity hardware. When contrasted with the repeated read/write actions of most other file systems it explains part of the speed with which hadoop operates. These tasks run in parallel over the computer cluster.
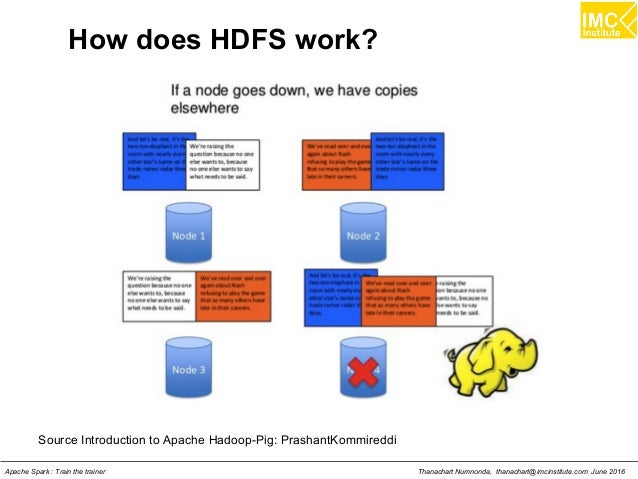
How Does Wi-Fi Work? | Brit Lab - YouTube from i.ytimg.com What do companies use hadoop? On a hadoop cluster, the data within hdfs and the mapreduce system are housed on every machine in the cluster. By default, hadoop uses the cleverly named hadoop distributed file system (hdfs), although it can use other file systems as well. Once all blocks are stored on hdfs datanodes, the user can process the data. How to get started hadoop? One is nodemanager on the slave machines and other is the resource manager on the master node. How do i get started with hadoop? That's why hadoop is likely to remain the elephant in the big data room for some time to come.
See full list on readwrite.com
They're just not constrained to use only sql, but can use other query languages to pull information out of data stores. Once all blocks are stored on hdfs datanodes, the user can process the data. They facilitate usage of a network of many computers to solve problems involving massive amounts of data. It divides a file into the number of blocks and stores it across a cluster of machines. But hadoop is not really a database: How do i get started with hadoop? It's the tool that actually gets data processed. You hear more about mapreduce than the hdfs side of hadoop for two reasons: When contrasted with the repeated read/write actions of most other file systems it explains part of the speed with which hadoop operates. These tasks run in parallel over the computer cluster. (2018)in this video you would learn, how hadoop works, the architecture of hadoop, core components of hadoop, what is namenode, datanode, s. It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs. But hadoop is still the best, most widely used system for managing large amounts of data quickly when you don't have the time or the money to store it in a relational database.
It provides massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs. Hdfs divides the client input data into blocks of size 128 mb. It divides the task submitted by the user into a number of independent subtasks. But hadoop is still the best, most widely used system for managing large amounts of data quickly when you don't have the time or the money to store it in a relational database. Mapreduce runs as a series of jobs, with each job essentially a separate java applica.
What is Hadoop and how does it work? - Dataconomy from dataconomy.com What can hadoop do for you? There is another element of hadoop that makes it unique: The file gets divided into a number of blocks which spreads across the cluster of commodity hardware. But hadoop is still the best, most widely used system for managing large amounts of data quickly when you don't have the time or the money to store it in a relational database. What do companies use hadoop? They're just not constrained to use only sql, but can use other query languages to pull information out of data stores. Learn about all the hadoop ecosystem componen. As the name suggests it stores the data in a distributed manner.
A) it integrates big data into a whole so large data elements can be processed as a whole on one computer.
It adds redundancy to the system in case one machine in the cluster goes down, and it brings the data processing software into the same machines where data is stored, which speeds information retrieval. They facilitate usage of a network of many computers to solve problems involving massive amounts of data. Depending on the replication factor, replicas of. Datastax' brisk is a hadoop distribution that replaces hdfs with apache cassandra's cassandrafs. In conclusion to how hadoop works, we can say, the client first submits the data and program. Mapreduce runs as a series of jobs, with each job essentially a separate java applica. It divides the task submitted by the user into a number of independent subtasks. One is nodemanager on the slave machines and other is the resource manager on the master node. B) it integrates big data into a whole so large data elements can be processed as a whole on multiple computers. The file gets divided into a number of blocks which spreads across the cluster of commodity hardware. The process is fairly linear: How do i get started with hadoop? What can hadoop do for you?
It adds redundancy to the system in case one machine in the cluster goes down, and it brings the data processing software into the same machines where data is stored, which speeds information retrieval. But hadoop is still the best, most widely used system for managing large amounts of data quickly when you don't have the time or the money to store it in a relational database. Learn about all the hadoop ecosystem componen. See full list on readwrite.com Before learning how hadoop works, let's brush the basic hadoop concept.
Apache Spark & Hadoop : Train-the-trainer from image.slidesharecdn.com They facilitate usage of a network of many computers to solve problems involving massive amounts of data. It provides a software framework for distributed storage and distributed computing. Once all blocks are stored on hdfs datanodes, the user can process the data. (2018)in this video you would learn, how hadoop works, the architecture of hadoop, core components of hadoop, what is namenode, datanode, s. The process is fairly linear: The file gets divided into a number of blocks which spreads across the cluster of commodity hardware. It's the tool that actually gets data processed. Datastax' brisk is a hadoop distribution that replaces hdfs with apache cassandra's cassandrafs.
Once all blocks are stored on hdfs datanodes, the user can process the data.
See full list on readwrite.com There are two daemons running for yarn. In a database that uses multiple machines, the work tends to be divided out: They're just not constrained to use only sql, but can use other query languages to pull information out of data stores. As the name suggests it stores the data in a distributed manner. There is another element of hadoop that makes it unique: Let us now summarize how hadoop works internally: A) it integrates big data into a whole so large data elements can be processed as a whole on one computer. One is nodemanager on the slave machines and other is the resource manager on the master node. In conclusion to how hadoop works, we can say, the client first submits the data and program. For its elastic compute cloud solutions, amazon web services has adapted its own s3 filesystem for hadoop. Large scale enterprise projects that require clusters of servers where specialized data management and programming. There's more to it than that, of course, but those two components really make things go.


{kind=link}